Been stuck at home all week due to the entire family being sick. BUT, I tried to put my isolation to good use by building a Lego version of Johnny 5 from Short Circuit. Progress is good so far!
There are times when you want to fetch data from your server that is occasionally changed. For example, getting the number of unread messages in an application. There are a few possible solutions for keeping the data up-to-date with the backend. 1) You can poll the server every X minutes, or 2) you can use “cache-and-network” to utilize the cache first, but also check the server for updated data.
Polling
If you choose to poll for new messages, you run the risk of your application constantly calling the server for data even though the user has not recently interacted with the page. Think, checking another tab or walking away from the computer for a while. While not detrimental, this results in a lot of wasted calls and network requests.
Cache and Network
This method ensures you always have the most up-to-date information from the server, but also results in a lot of needless calls to the server. The client is constantly saying, “Ok, I’ll use the cache, but let me still call the server to check for updated data.” This query/hook may run multiple times on a single user interaction and is still to aggressive for data that only updates every few minutes.
The Solution
What we really want is the best of both worlds. We want to utilize the cache as much as possible, but also set an expiration for when to grab fresh data from the server. We can use a simple technique of utilizing Map and dates to accomplish this goal.
We’ll simply make a unique “key” for our query and record the last time we fetched that key. When we call useQuery, we pass it our “key” and the expected expiration time. If the “key” is still valid, we return to useQuery the fetchPolicy of “cache-first.” This means, use the cache if it exists and otherwise fetch from the server. If the “key” is invalid, we call useQuery with “network-only” which calls the server to refresh the data. And at the same time, we update the last fetched time of the key.
Let’s take a look at an example of the getFetchPolicyForKey() function and its implementation.
useUnreadMessages.ts
import { getFetchPolicyForKey, ONE_MINUTE } from "./hooks/useCacheWithExpiration";
export const useUnreadMessages = (): number => {
let unreadMessages: number = 0;
const { data, error } = useQuery(UNREAD_MESSAGES_DOC, {
fetchPolicy: getFetchPolicyForKey("unreadMessages", ONE_MINUTE * 5),
});
if (isDefined(data)) {
unreadMessages = data.unreadMessages
}
return unreadMessages;
}
And here’s the implementation of the cache check and when to return each fetch policy.
getFetchPolicyForKey.ts
// Record of keys and the last fetched timestamp
// These are universal for all calls and hooks
const keys = new Map<string, number>();
export const ONE_MINUTE = 1000 * 60;
/**
* This function accepts a unique key and an expiration date. It returns "network-only" if the cache key is expired
* or "cache-first" if the key is still valid for the given expiration time
*
* @param key - the unique name you want to give this expiration key
* @param expirationMs)
*/
export const getFetchPolicyForKey = (key: string, expirationMs: number): WatchQueryFetchPolicy => {
const lastFetchTimestamp = keys[key];
const diffFromNow = lastFetchTimestamp ? Date.now() - lastFetchTimestamp : Number.MAX_SAFE_INTEGER;
let fetchPolicy: WatchQueryFetchPolicy = "cache-first";
// Is Expired?
if (diffFromNow > expirationMs) {
keys[key] = Date.now();
fetchPolicy = "network-only";
}
return fetchPolicy;
};
I was recently adding Flow typing to a HoC and ran into a specific use case. The HoC injected its own function into the child component while also using of the of child props in the injected method. So here's how to properly flow type it so that consumer of the HoC will enforce the typing of the child.
First, add the type for the prop you will be injecting into the child
type InjectedProps = {
myInjectedMethod: () => void
};
Second, add the type for the prop you need to use from the child
type OwnProps = {
videoId: number
};
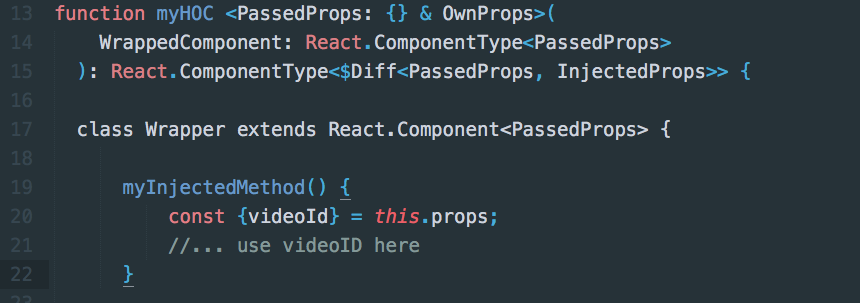
Last, update the HoC wrapper as follows
function myHOC <PassedProps: {} & OwnProps>(
WrappedComponent: React.ComponentType<PassedProps>
): React.ComponentType<$Diff<PassedProps, InjectedProps>> {
class Wrapper extends React.Component<PassedProps> {
Here's what each of those lines is doing:
This is ensuring that for the calling of this HoC, we enforce the typing of the child and add the requirement for our own props.
function myHOC <PassedProps: {} & OwnProps>(
This simply passes along the typing of the child component.
For a weekend project I built a backlight array for my TV which gives off ambient lighting according to what colors are being shown across the edges of the screen. Powered by a microduino and Abalight software for Mac.
According to the experts, backlights offset the brightness of the screen by lighting up the entire wall, while also giving the impression that the movie is bigger than just the screen. I just say “woot.”
I recently had an issue with a server hosted at OVH.com. One Saturday, it completely failed to boot and there was no SSH access. After a little pleading with OVH to fix the server(since I had no access) , I was flatly told “No” several times. This was a dedicated server and as such, I was responsible for all aspects of its software. “But your physical disks are failing to mount!” No help. Grrr, ok I can solve this.
Here’s the only problem, I don’t even know what the error is on boot! I can’t see any of the boot screen, so I don’t know where its failing.
OVH has a convenient feature know as Rescue Mode which allows you to boot to an alternative OS, so you can mount and correct any issues on the primary drive. Utilizing this feature I got access to the disks and RAID array. Everything seemed fine, but I ran through all the checks to be sure.
Hard Disks – No errors
Raid Array – Needed to be resynced, but does not fix boot
FileSystem – OK
Boot Logs – No help
Partitions – Disks are out of order, but does not fix boot
At this point, I’m out of ideas, so I call OVH one more time and ask them to look at the boot screen and tell me where its stuck. They agree and tell me it boots to GRUB> prompt and stops. Ok, this is good information.
I log back into rescue and scour the internet for a way to fix this. The answer is found in an obscure ubuntu forum, which perfectly describes a way to reset the grub loader on each disk in the array, when utilizing a rescue mode.
$ sudo fdisk -l (From this you need to find the device name of your physical drive that won't boot, something like “/dev/sdxy″ - where x is the drive and y is the root partition. Since I was using a software RAID, root (/) was on md1)
$ sudo mount /dev/sdxy /mnt (Mount the root partition)
$ sudo mount --bind /dev /mnt/dev
$ sudo mount --bind /proc /mnt/proc
$ sudo mount --bind /sys /mnt/sys
$ sudo chroot /mnt (This will change the root of executables to your your drive that won't boot)
$ grub-mkconfig -o /boot/grub/grub.cfg (insure that there are NO error messages)
$ grub-install /dev/sdx (NOTE that this is the drive and not the partition. try grub-install --recheck /dev/sdxy if it fails)
Ctrl+D (to exit out of chroot)
$ sudo umount /mnt/dev
$ sudo umount /mnt/proc
$ sudo umount /mnt/sys
$ sudo umount /mnt
Reboot!
Hopefully this will save someone some agony in the future and give you a few hours of your life back.
Here’s my recent talk entitled “Chasing 60fps, Using ReactJs to Rebuild Netflix.com.” We discuss both the advantages and challenges of building with ReactJS for the new Netflix UI.
I recently need to set up caching for a very slow API service I was working with. However the app I was working with forced a query param of “timestamp” on all requests. This effectively killed the cache because all api requests were flowing through a single endpoint, and only the query params differentiated the requests. So here’s how to set up caching and strip out query params with nginx.
http {
# Create a storage location for
# caching and call this location "my-app"
proxy_cache_path /data/nginx/cache levels=1:2
keys_zone=global:10m
max_size=100m inactive=60m;
server {
location /api/ {
# Strip out query param "timestamp"
if ($args ~ (.*)×tamp=[^&]*(.*)) {
set $args $1$2;
}
# Use the "my-app" cache defined above
proxy_cache my-app;
# Only cache 200 responses and cache for 20mins
proxy_cache_valid 200 20m;
# Create a unique cache key
proxy_cache_key
"$scheme$request_method$host$uri$is_args$args";
# Proxy the request
proxy_pass http://myapi.com;
}
}